Time to reminisce; to think back to the first proud moment when you finally owned your first computer. Standing there on your desk, most likely ready to offer you knowledge and experience that did definitely affect your life. Maybe even your first trembling step towards becoming a web developer?
My first computer was an IBM PC. It had a Pentium 120 Mhz processor and 12MB of RAM together with an 850 MB hard drive. The RAM was eventually updated to 38MB and the difference was as clear as night compared to day. And to remember that I actually learned Photoshop on this machine! 🙂
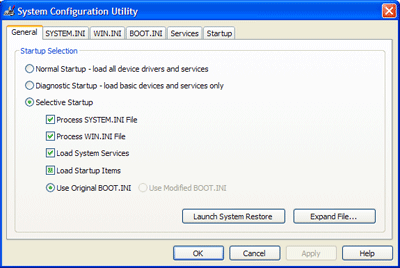
Does your PC feel sluggish? It takes forever to start? It hogs memory like nothing you’ve ever seen but you have no clue to why? Let me give you a little tip: take a look in MSCONFIG (simply press Start > Run and type in “MSCONFIG”, or look at the How to use MSCONFIG guide).
The part I want you to focus on in that dialog is the Startup tab. Click on it and you will find all programs and process that are run when Windows loads, even though you most likely couldn’t locate them in the Startup folder or each individual program’s settings. I strongly advise you to go through every item you find there and make sure it’s needed by you and/or Windows in your everyday work.
I decided to do this last weekend, just because my home laptop was a little slow and because I have no life (at least not when my daughter is sleeping and my girlfriend isn’t at home). Besides all the totally unnecessary processes I found there, to my horror I found a Trojan/>Backdoor. Being a Windows user, I naturally have a firewall as well as continuously updated antivirus program. I run Windows Update frequently and I use Firefox as my main web browser, so people shouldn’t be able to get to me through an IE glitch.
So how did this happen? I have no idea. How long has it been there? Clueless. But very very annoying and frightening. I want to be able to use a computer connected to the Internet without having to keep it in an atom bomb-proof safe… 🙁
In March, the biggest web event of the year (at least in my eyes) is taking place in Austin, Texas, USA; its name is SXSW Interactive. There will be speaking performances from virtually every interesting person in the business, and the networking possibilities are infinite. And now I’m lucky enough to announce that I’m going! 🙂
I spoke to Roger the other day, and he informed me that he had decided not to go. I guess that means I’m the only Swede, no, correction, the only blogging Swede that I know who is going; I’m traveling there together with a Swedish colleague, Daniel. He is a hilarious guy, so I’m fairly sure that we will have a lot of fun trying endure all the hours on different flights (yes, it’s a pretty long journey from Stockholm to Austin).
Anyway, I do hope I can be a good representative for Swedish web development, and I look forward to learning a lot and to meeting very inspiring people as well a number of friends I’ve made in the web development community, almost too numerous to mention. And if I did, you would just regard me as a namedropping freak, so I won’t do that. 🙂
So, what the hell do I look like then? How do I find Robert Nyman? Well, I look something like this:
I’m staying at the Hilton, where a number of cool people are also staying. Are you going? Write a comment and let me know!
I saw this four things meme going around the blogging world but was kind of hoping it would miss me. Just as things seemed to quiet down, though, Roger got me. Make sure to follow the links from this post, some of them are actually interesting! 🙂
Here goes:
Four jobs I’ve had in my life
Working in a gas station
Packaging trucks for UPS
Sales man
Web developer
Four movies I can watch over and over
I love movies, and I also have reviews of some in my movies section. Not sure I would really watch Big Fish over and over, but it’s an amazing movie and everyone should see it.
Technically speaking, he hasn’t got a blog (to my knowledge), but I still just have to name him as a runner-up, because I know he would put together an outstanding (and maybe horrifying?) list: Mr. Robert Wellock.
I would actually want to tag each and every one of you kind enough to read my ramblings, so please please feel free to share your four items in any or all of the categories below in a comment!
With the humble title of this post, I guess I really need to add that these ways mentioned below are the ones I’ve experienced to be very reliable to get a good search engine ranking. Naturally it varies a lot, but I get somewhere between 28 – 45% of my visitors from pure Google searches, out of just having a high ranking (and sometimes for terms that amaze me :-)). These are my advices:
Semantic code
Make sure you write semantically correct code, meaning that you need to use the correct element for the right situation. It is all about how you mark the words you are using, and how and in what context you want them to be interpreted.
Friendly URLs
Make sure you have URLs with a good descriptive value, as opposed to one being made up of just a lot of parameters. There are different tools and settings to achieve this in most, if not all, web development environments. For instance, these two links both lead to the same web page:
If you get mentioned with good words in an appropriate context, especially from a web site that has a good PageRank, it will help push you up the search engine list.
These are the only tips I can give you; basically, it’s just about good web development practises and maintaining good relations with other web site owners.
I’m sure there are good SEO companies out there, but the ones I’ve come across have all been unprofessional and/or been using very suspicious methods. And as soon Google update their algorithms, there’s a big chaos when some SEO’s dubious work fail, since some of their tricks have been found out and taken care of. Then, naturally, it backfires so their customers get a very bad search engine ranking.
Just do as I suggest above; code properly and you will be safe. Look around to see how good search engine ranking most web developing blogs get, just because they know how to implement a web site in a correct manner.
Come on, give us a bad example
Sure, but only since you asked for it. Recently the web site http://www.larmdirekt.se/was brought to my attention. If you navigate to their web site and disable CSS in your web browser (Ctrl/Command + Shift + s is one way to do it if you use the Web Developer extension in Firefox), alternatively view the source code of the page.
In the footer, you will then find a link with the text “y”, which leads to the page http://www.larmdirekt.se/laarm/. Make sure to turn off JavaScript in your web browser and navigate to that page and you will not believe your eyes: a little link farm. If you surf around those links you will, amongst others, find the names of some fairly large Swedish companies, and the best thing of it all: the name of the SEO company in the title bar.
So, go check out the code of your own web site right now, or ask your SEO what methods they use.
I’m sorry, but I just have to share this amazing list with you: Top 10 Wackiest Conspiracy Theories. I mean, a list with the items mentioned below is just to good to miss!
Dinosauroid-like Alien Reptiles are dominating the World
Apollo 11 Moon Landings were faked by NASA
September 11 was orchestrated by the U. S. government
Barcodes are really intended to Control people
Charlemagne never existed, is a fictional character
The Truth is out there, on Area 51
Microsoft sends messages on Wingdings Font
U.S. military caused the 2004 Indian Ocean Tsunami
The IE team has made a very wise decision to natively support XMLHttpRequest in IE 7. XMLHTTPRequest is the foundation of any AJAX usage, and I for one applaud the move to make it available without the demand for using ActiveXObject.
Using object detection, one can easily make your code backwards compatible as well:
var oXMLHttp;
if(typeof XMLHttpRequest != "undefined"){
/* Code for:
IE 7
Firefox, Mozilla etc
Safari
Opera
*/
oXMLHttp = new XMLHttpRequest();
}
else if(typeof window.ActiveXObject != "undefined"){
/*
Code for:
IE 5
IE 6
*/
oXMLHttp = new ActiveXObject("Msxml2.XMLHTTP");
}
Apparently Opera’s claim to support document.all in conjunction with not mimicking it exactly like IE led to some problems in Opera 9. Thanks to Ash Searle who tipped me about this and also explained what the problem was. The code below and the JavaScript file to download are updated.
Since we all have to face a new hard tough week now, I thought I’d brighten your day by giving you some code that might be useful.
Ever run into a situation where you want to get an array of all elements with a specific attribute? Or even want elements with a certain value for that chosen attribute, as well? That’s not a problem anymore; let me present getElementsByAttribute.
/*
Copyright Robert Nyman, http://www.robertnyman.com
Free to use if this text is included
*/
function getElementsByAttribute(oElm, strTagName, strAttributeName, strAttributeValue){
var arrElements = (strTagName == "*" && oElm.all)? oElm.all : oElm.getElementsByTagName(strTagName);
var arrReturnElements = new Array();
var oAttributeValue = (typeof strAttributeValue != "undefined")? new RegExp("(^|\\s)" + strAttributeValue + "(\\s|$)") : null;
var oCurrent;
var oAttribute;
for(var i=0; i<arrElements.length; i++){
oCurrent = arrElements[i];
oAttribute = oCurrent.getAttribute && oCurrent.getAttribute(strAttributeName);
if(typeof oAttribute == "string" && oAttribute.length > 0){
if(typeof strAttributeValue == "undefined" || (oAttributeValue && oAttributeValue.test(oAttribute))){
arrReturnElements.push(oCurrent);
}
}
}
return arrReturnElements;
}
The parameters are:
oElm
Mandatory. This is element in whose children you will look for the attribute.
strTagName
Mandatory. This is the name of the HTML elements you want to look in. Use wildcard (*) if you want to look in all elements.
strAttributeName
Mandatory. The name of the attribute you’re looking for.
strAttributeValue
Optional. If you want the attribute you’re looking for to have a certain value as well.
And these are a couple of examples how it can be called:
A while ago I read Garret Rogers’ post The personalization war, which in part inspired me to write this introduction to different personalized start pages. So what are those, really?
The main purpose of such a start page is for you to get a good and easy overview of a lot of things, including the feeds you follow. Different services also offer different gadgets that you can use, such as seeing your e-mail inbox. Naturally, one of the most useful parts of this is that you have access to the same start view and information wherever you are and whatever computer you are using.
Most of them are, of course (sigh…), in a beta state, so I haven’t really taken that into my observations. I’ve tested them in different categories, and I name a winner for each and finally, a total winner. Live/Start is developed by Microsoft, but I’m not sure if Start will still be around and if they’re putting all their energy into Live now. Both are pretty much the same service right now, though.
Design
Google Personalized Home’s service looks pretty much like all of the other Google services, as opposed to Netvibes and Live/Start who have got very lean interfaces. Netvibes has also got a nice distinct background and borders around its parts to easier tell them apart. My Yahoo! offers a lot of themes, and each and every one of them almost makes me barf.
Winner: It’s a tie between Netvibes and Live/Start.
Usability
All of them, except My Yahoo!, rely heavily on an AJAX approach with drag and drop to position your different parts wherever you feel like. Netvibes and Live/Start also offers the possibility to expand and collapse different parts, where Netvibes also has links for expanding/collapsing all parts. Netvibes is the only one showing you a number of unread posts for each of your feeds.
Google Personalized Home and My Yahoo! only present direct links to the posts in your feeds, whereas Netvibes and Live/Start present the text for each feed when a link is clicked, together with the other posts for the same feed, and there you can choose to expand or collapse the text for all of the feed’s posts.
Netvibes and Live overlays a “page/window/layer (yeah, I’m sorry for that word :-))” that fills the entire web browser window when the links are clicked, as opposed to Start that just opens a small one. Start’s behavior is definitely the one of these I prefer.
Live/Start also offers small arrows after each post in a feed which is a direct link to the post in question. This would have been great, if they haven’t added the functionality to these links to automatically open a new window. Extremely annoying. This is 2006, ok? People want to choose themselves if they want to open a link in the same window, a new window or a new tab; don’t force a behavior on users. And if you’re so worried most users won’t get, just offer this as a setting then.
I wish Netvibes would also have these arrow links, but naturally not with the behavior mentioned above that Live/Start have. In the overlay that is opened up, Netvibes’ also dreadfully opens new windows when each direct link to another web page is clicked. Stop it! Now!
Settings-wise, Live/Start is the winner with offering you how many columns you want to use, from one up to four columns. My Yahoo! is the only other service offering this, with the choice of two or three columns. My wish is that all of them should really offer a way to see the text for each feed post in the same view when it’s clicked, and also to expand or collapse all posts for a certain feed or the entire web page. I also wish Netvibes would add a way to mark all posts for all feeds read.
Another thing that blows my top is that the sign in-link on Live for a long time didn’t work in Firefox. Then they fixed it, but apparently added some new update, so now it’s broken again. It’s just a link, dammit, how hard can it be? And the number of dead links and things of inconsistency one stumbles on while using My Yahoo! are too numerous to mention.
If it hadn’t been for Live/Start forcing me to use a Microsoft Passport account, I would’ve declared a tie between Live/Start (because of being able to choose what number of columns to have, and Start also for its nice reading window) and Netvibes (for its unread items feature). However, because of that, it tripped Live/Start at the finishing line.
Winner: Netvibes.
Accessibility
I turned off JavaScript, and not surprisingly, none of them had a full proper fallback. Netvibes and Live/Start didn’t even render any content nor give me a message saying that I had to have JavaScript enabled. Most of the links didn’t work either for Live/Start when tabbing to them and then pressing Enter. Google Personalized Home rendered the content fine but told me that I had to have JavaScript enabled, and has a text saying that it now works on mobile devices (I haven’t verified this). My Yahoo! kind of worked without JavaScript except for some parts.
Winner: My Yahoo!
Importing/exporting OPML
The most efficient way to use your feeds in different services is to have them categorized in an OPML file and then just import them. Netvibes and Live/Start offer importing as well as exporting of OPML files, although, for some, reason, Netvibes didn’t work correctly with my OPML file that seems to work fine for all the other services on the web. The problem was that I could indeed import the feeds but then the grouping went wrong so I could never see the content of any feed or add it to my page.
Google Personalized Home and My Yahoo don’t offer neither of these, which, to me, is shocking.
Winner: Live/Start, for working flawlessly with feeds.
Gadgetry
Google Personalized Home offers you seeing your GMail inbox (surprise), My Yahoo! offers you to see your Yahoo! Mail (another shocker) and Live offers you to see your Hotmail (yeah, I’m trembling with excitement now…). However, Live also has a number of other gadgets for you to use, where Netvibes seems to have the best ones. Netvibes have, amongst others:
Mail (GMail, Yahoo! Mail or any other POP mail you want to add)
Webnote
To Do List
Delicious
Winner: Netvibes.
Code quality
All of them have validation errors, but Netvibes seemed to be the only one that didn’t have well-formedness errors or invalid elements. Google Personalized Home and My Yahoo! didn’t even have a doctype. Semantically, they were all pretty poor…
Winner: Netvibes.
The winner is…
If you’ve mustered enough strength to read this far, you have probably guessed that it is: Netvibes. Overall, they offer the most stable, reliable, usable and customizable service. While it’s far from perfect, it’s definitely my pick of the pack. Are you using any of these, or some other personalized start page service? Let me know!
Congratulations, all web developers! In IE 7, the select element and its rendering is finally fixed, according to the For the SELECT few… post at the IEBlog! Support for z-index and title has been added, as well as for zoom (Yay! ;-)).
I though I’d share with you how you can really enhance your web searching by customizing the built-in search in Firefox, and perform more defined searching. If you aren’t aware of it, you have the possibility to add a lot more search engines to the Firefox search bar; a list of very interesting search engine add-ons can be found in the Search Engines web page.
Naturally, using the mouse to select the search field and a search engine is just tedious as well as strenuous, so let me provide the shortcuts you need to make your life easier:
Ctrl/Cmd + K to set focus to the search field.
Ctrl/Cmd + arrow up/arrow down to change between installed search engines (focus has to be set to the search field first).
Alt/Option + arrow up/arrow down to display the list of installed search engines and then arrow up/arrow down followed by Enter to choose one of them (focus has to be set to the search field first).
This post is mostly applicable for Swedish readers, but I believe most of you in other countries stumble across this fairly frequently too.
Here in Sweden we have a publication called Internetworld , whose target group is mostly private users and small businesses. Their articles mostly deal with business gain, short press releases what has happened in the field of technology with things like new services on the web, Firefox increasing its user base etc. Out of general interest I read it, amongst a lot of other publications, just to stay on top of what’s going on and what people are talking about.
When I had worked a while in the internet business, I soon realized that they aren’t always exactly spot on with their articles, especially when it comes to technology choices, coding tips and its likes. However, what they’ve written has mostly been harmless and can at least be of some help to amateurs starting to code.
However, I just browsed through the latest issue with an article entitled “Web standards part 1 – Adapt the web site for different web browsers”. Just reading the headline, I realized it probably wasn’t going to be good. After going through it I came to the conclusion that it isn’t as bad as I first thought, they do, at least partly, try to convey the message that there actually is something out there called web standards and it is there for the device “Code once, run everywhere” kind of equivalent for web code.
Unfortunately, though, they have some parts and quotes that I sincerely think will hurt new web developers’ attitude towards web developing and that’s the reason for me writing this. They briefly touch on the fact that there are different interpretations by web browser vendors how web standards should be implemented. While that is to some degree true, it’s seldom knowledge that beginners need to know, it’s usually only interesting on a pretty high level, as long as you start out the correct way when you build your web sites. And it’s rarely a problem when you write HTML/XHTML, it’s usually when you code CSS that this will be more evident (which will, as I understand, be touched on in an upcoming part in this series).
The conclusion of the article is to follow web standards if you have no idea about your target group; otherwise, offer them an enhanced and web browser-specific version that only works under certain circumstances. Another conclusions is that web standards is an “advanced technique” and question if it’s worth to require that out the users to have such modern web browsers to be able to use your web site; talk about not understanding web standards.
I don’t know where to begin with to describe how damage such an attitude will do. Sure, naturally most if not every web site out there will work better in a later version in, say, Internet Explorer or Firefox than in Netscape 4 but that doesn’t give you the right to shut out users with an older web browser. It’s all about progressive enhancement.
Another thing is that even if you do know a lot about your visitors and the statistics, that situation can almost change overnight. Build an Internet Explorer-version on proprietary code just to realize a month later that many of them have started using any other web browser out there. Also, does anyone really know how many web browsers there are out there? Hundreds and hundreds, let me tell you that. Different web browsers on different operating systems, PDAs, cell phones, digital TV boxes et cetera. The only way to make sure that your code will work is to follow web standards. No, web standards will not solve your every problem, but that’s the closest you can get and definitely your best bet if you’re serious in what you do.
Let me quote some pieces in the article:
There are a number of reasons where you gain from following web standards, but here are also occasions when you don’t, which we will explain in some of the following tips.
After that, I never find any tip where the difference is proved. Also, that’s just the mindset that’s so dangerous and there has to be a realization that while web standards maybe won’t save the day automatically, they will never hold you back either.
In modern HTML, that is often referred to as XHTML…
What kind of crap is that? There’s HTML and there’s XHTML; they are two different things and none of them are really more modern that the other. Something that really bothers me is that that isn’t even mentioned and doctypes are totally left out. No wonder you think there are differences out there if you don’t know how to choose a doctype and what effects that choice will have on the rest of the code.
Usually the unit px (pixels) is the one unit that gets interpreted most alike amongst the web browsers
While I kind of get what he’s going for, like percentage rounding errors in some web browsers and its likes, talk about killing the accessibility factor. You can’t make such a statement that will give such repercussions without explaining it in a more detailed way. And what about ems? Ever heard of those?
Conclusively, maybe I’m way too hard on this guy. After all, I do sincerely believe that he meant well with the article and tried to help people, but my fear is just that he did as much harming as helping; hence this post.
As of lately, I’ve been trying to move my program/service usage online more and more, to make it accessible from any computer and also not to lose information in case of a computer crash. Part of that has been finding a service to follow all the feeds I subscribe to. If you don’t know what a feed is, read Wikipedia’s Web feed definition.
So, deciding which ones to test, amongst other sources, I turned to the statistics for this web site to see what the people who are subscribing to my feeds are using. My conclusion was that the four that seemed most popular were:
The important thing to think of when using these kinds of services is that they should support importing and exporting of OPML files. Then you can just move your feeds from service to service and save them in a file for later reference, instead of entering all the feeds over and over again.
Don’t regard this as a professional review but rather just as a regular computer user testing them out. My impressions were:
Bloglines
From what I gathered, Bloglines seems to be the most popular service online and generally I think it’s ok to use, no more, no less. I don’t like the layout using frames, although I really have to give them credit for their excellent PDA version (the only serviced I’ve had the opportunity to test on a PDA). My preferred usage is to keep my read and unread posts together in the order they were posted by the author, together with an indication in the navigation of how many unread posts there are in that specific feed. Bloglines, as well as all the other services have that indication.
However, one thing that bothers me is that the read feeds disappear from the default view when I click on a feed. It is possible to retrieve them again, but that requires extra steps. An alternative to this is to use Clippings to save your favorite posts, but that’s not as interesting to me.
NewsGator
NewsGator is very similar to Bloglines but with a slightly more appealing layout. It implements the same things with removing read posts from the default view and having Clippings for favorites. The thing with NewsGator, though, is that the whole feed disappears from the left hand navigation, if it doesn’t contain any unread posts. Very annoying.
Google Reader
Google Reader has a default layout which is very sparse but good, and it displays only the latest updated posts. It also has support for keyboard shortcuts, of which I’m a real aficionado. But, as soon as you click the Your Subscriptions link, it takes up the entire top part of the web page.
I would really like to see a way to check posts feed by feed without losing so much space of the web page. Google Reader definitely has potential in my eyes, though.
Rojo
First, I love Rojo’s front page with the Most Read Stories and Recently Tagged Stories, it’s a great and simple way to see what’s talked about right now. Rojo has also taken a little different approach with tagging posts, something I really like and it makes it very easy to find mine and other people’s posts for a certain topic.
After that you have a number of ways to view your feeds, and the different options you make should stick. Unfortunately, expanded blocks in the Feeds tag view doesn’t seem to be consistent/stable when it comes to that, but otherwise it works fine. Overall, it does seem just a tad slow, though.
Conclusion
I didn’t really find any service that was perfect, but out of these I have to say that Rojo is my pick. One of the reasons for that was the updating frequency, the other services can lag behind up to half a day; I want my information instantly! 🙂
So now I use Rojo and another similar service that I will tell you more about another day. I do urge you to test these out; maybe one or several of them are spot on for you.
Are you already using any of the above, or some other service that you would like to tip me about? Let me know!
In common web development people use query strings to pass parameters to the receiving web page. This technology is available in basically every language dealing with the web, such as ASP.NET, PHP, JSP, JavaScript etc.
Sure, query strings aren’t always the best way to do things, it depends on the situation, but in my opinion there are a lot of cases where it’s a justified and good approach. There are definitely a lot of scenarios when one can’t post forms to achieve this effect, but instead has to resort to query strings, for instance, when it comes to making a direct page available for bookmarking.
And yes, one can implement so-called friendly URLs, but from what I’ve seen it isn’t really the best approach either.
However, as most web developers are aware of now, is that if you use query strings it will negatively affect your search engine ranking. My question is: why? Should we change a common web developing standard just because search engines have a hard time dealing with it? And who are they to judge, using query strings extensively themselves?
The links are leading to articles at Newsvine where you will need to sign in. If you’re interested in reading these articles, write a comment and I’ll send you an invite.
What I find interesting about this is that they will make no attempt to stop people from installing Windows on these machines, meaning that you can have Mac OS X or Windows, or *gasp* both! Sounds like a pretty interesting setup to me!
However, not sure what the pricing is in your country, but here the new Macs are still terribly overprized compared to the PC equivalent. But I guess you gotta pay for your high maintenance life style… 🙂
A while ago I was invited amongst a lot of other people to beta test the new service Newsvine. I know that the title of this post might imply pessimism, but it’s not meant like that; it’s a rhetorical question.
So, first, what is Newsvine? Basically, you have a number of options as a user. You can:
Read articles collected from around the web
Write your own blog
Seed articles, i.e. have a list of links with description to news that you find interesting
Then you can either comment on a post/article, live chat about it or endorse it so it gets a higher ranking. You tag all your posts and articles, and you can search or browse pre-defined categories in a top menu of the web site, or through a search at the top where you can specify a certain tag to look for. You can also add authors or tags to a personal watchlist.
One of the things I miss as a user is a way to only search through the links I’ve tagged as, for instance, “technology”; as of now, if I click such a tag link, I get to see everyones’ posts and links with that tag. Sure, I guess they can implement a so-called tag cloud, but visually, to me they’re mostly annoying.
At first I had a hard time finding any usage for it; there are a lot of different services out there to track news and other information, especially in the technology department, and most people have an abundance of feeds they also follow. I think one of the fundamental ideas of Newsvine is to gather a lot of new and, not to say the least, useful information in one place. So I spoke to one of my Dutch vatos, Mr. Ates, who was trying to convince me that it is indeed a useful service (also, make sure you read his Newsvine: the organic web, organized).
Now I like it a little better, however I’m not really sure I use the service as intended, though. To me, it’s more like a better version of http://del.icio.us/ where I can collect and tag articles, mostly my own that are published here, than for following news. Not sure if this is frowned upon as self-endorsement, but I guess we’ll have to see about that one.
So I guess I feel a bit ambivalent about it all. It might happen, and then again it might not. So far I’m not addicted, but maybe the future and using it some more will change that. I will say one thing, though: I’m really interested in if this will be a hit or not!
Are you already a Newsvine user? Then let me know what you think of it.
PS. As of now, Newsvine is invite-only, so write a comment if you want an invitation to check out the service. DS.
It has been some talk about this lately, and Google has now released Google Pack. Basically, it’s a package of different software that’s there to make your computer life better. I guess this is targeted at users who aren’t very computer savy, or people that just want it all bundled. Google’s first step towards world domination, maybe…? 🙂
The Google software is pretty obvious, but I think Norton with a subscription that ends after 6 months will annoy people. My guess is that they will perceive this as a free package that will just work. No fees, no additional download, no extra costs.
The other shocker is Real Player. Is it a joke? I mean, really, come on. We all know how hard Real Player sucks. Not the company I’d like to get associated with, I tell you that.
Most people I have met have an opinion about this, and I’ve also heard that some companies have a policy that forces the employees to turn off the computer after every working day, and if it’s a laptop they also have to lock it into a cabinet or a safe.
Personally, I always put my laptop at home into hibernation by only closing the lid, and try to remember to restart it once a week or so to avoid it getting sluggish. At work I usually leave the computer on from Monday till Friday, probably out of laziness when it comes to restarting every application, opening all files and projects etc, but I then shut it down every Friday before I go home.


 .
.